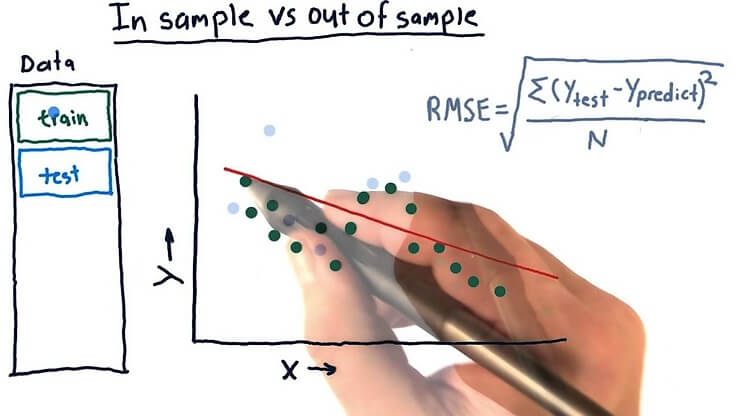
在數據分析中,我們通常將回測數據分為樣本內數據和樣本外數據。這種方法有助於提高模型的準確性和可靠性。例如,假設我們有10年的足球數據,可以將前5年作為樣本內數據,用來訓練我們的AI模型。接下來的5年則作為樣本外數據,用來測試和驗證模型的表現。
通過這種方法,我們能更好地識別過度擬合(overfitting)的風險。在樣本內數據上訓練完成後,將模型應用於之前未見過的樣本外數據,進行評估。如果模型在樣本外數據上的表現明顯不如樣本內數據,則表明該模型可能過度擬合。
這種分割數據的方法不僅可以提高我們對模型的信任度,還能幫助我們及早發現和修正可能存在的問題。我們應該時刻關注樣本內和樣本外數據的結果差異,以確保模型的穩定性和適應性。