利用數據科學預測博弈結果
機器學習的應用範圍十分廣泛,其中一個值得關注的應用領域便是分析博弈數據,並預測博弈結果。在本篇文中,我們將以足球博弈為例,展示如何利用機器學習技術來分析博弈數據,並預測賽果,進而制定策略,爭取優勢。透過簡單易懂的步驟,以及實際操作示範,深入瞭解機器學習在博弈分析中的應用,並啟發數據分析與策略制定新的思考模式。
數據蒐集與準備
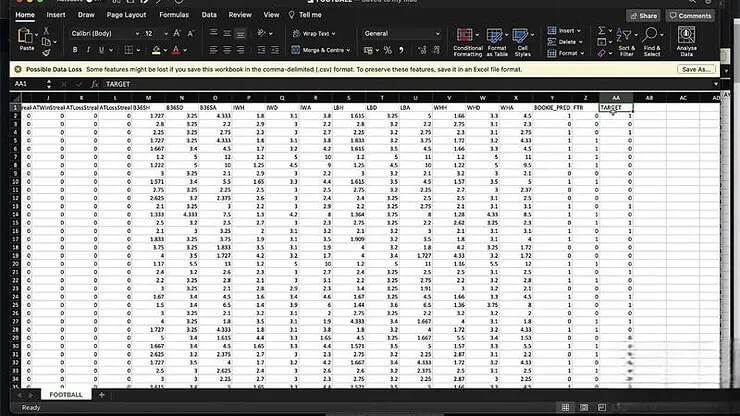
首先,我們需要取得相關數據。Kaggle 是一個著名的數據平臺,其中包含大量公開可用的數據集。我們在 Kaggle 上搜尋與足球博弈相關的數據集,並找到一個包含足球比賽結果和賠率數據的數據集。這個數據集包含了比賽日期、主場球隊、客場球隊、以及各家博彩公司的賠率等資訊。建議在選擇數據集時,應該避免使用比賽過程中發生的數據,例如進球數或紅黃牌數量,因為這些數據in-game metrics在賽前屬於未知變量,可能導致數據洩露(data leakage)或引入預測偏差(prediction bias)。理想的策略是利用比賽開始前的資訊,例如球隊歷史戰績、球員狀態等等,來預測賽果。
數據預先處理
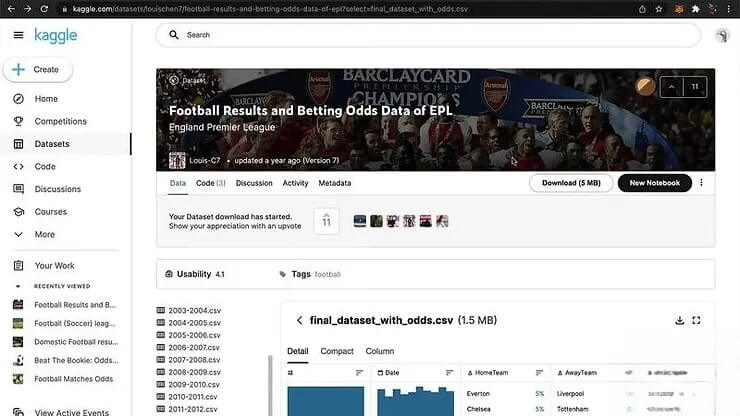
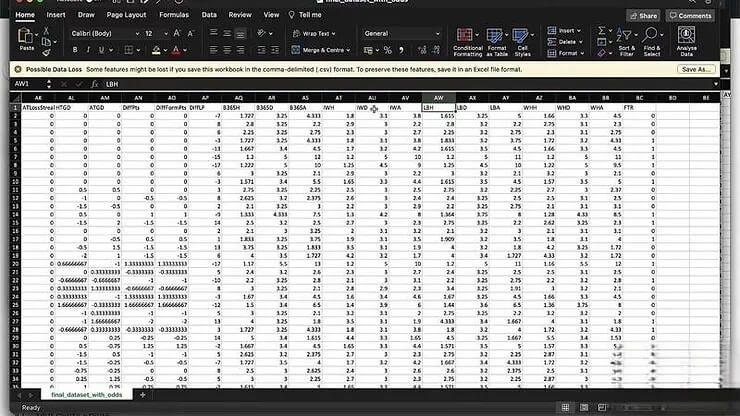
取得數據後,需要對數據進行預先處理。使用 Excel 進行數據預處理,首先將文字類型的數據轉換為數字。例如,將主場球隊和客場球隊的名稱轉換為數字編碼,方便機器學習模型處理。根據各家博彩公司的賠率數據,建立一個新的欄位,稱為「博彩公司預測」。這個欄位代表博彩公司對於主場球隊獲勝的預測結果。例如,如果博彩公司的賠率顯示主場球隊獲勝的可能性較高,則「博彩公司預測」欄位的值將為 1,反之則為 0。

機器學習模型訓練
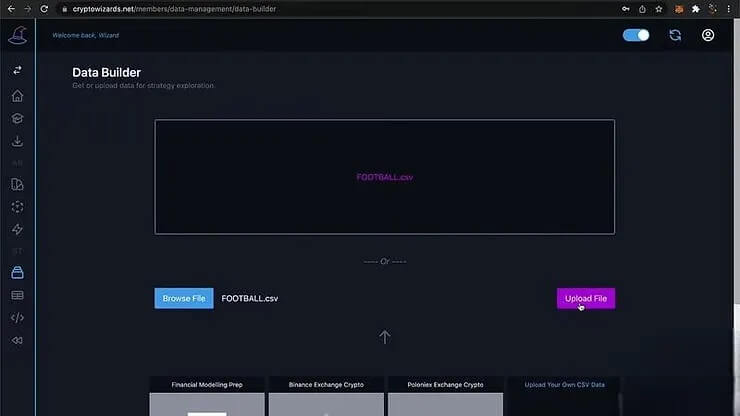
完成數據預處理後,我們使用 Crypto Wizards 平臺上的機器學習訓練工具,來訓練一個機器學習模型。這個模型的目標是預測「博彩公司預測」欄位的值,也就是說,預測博彩公司是否正確預測了主場球隊的獲勝結果。在訓練模型時,我們特意將「比賽結果」欄位排除在外,因為這個欄位等同於預測結果本身,包含了未來資訊,會導致模型過度擬合。此外,我們選擇了「精準度」作為模型優化的目標,因為在博弈交易中,精準度代表了當下做出交易決策時的正確性,而非所有可能交易決策的整體正確性。機器學習訓練過程需要調整模型參數,例如訓練輪數、學習速率等,以達到最佳的預測效果。我們可以任意調整參數,並觀察模型的效能表現。
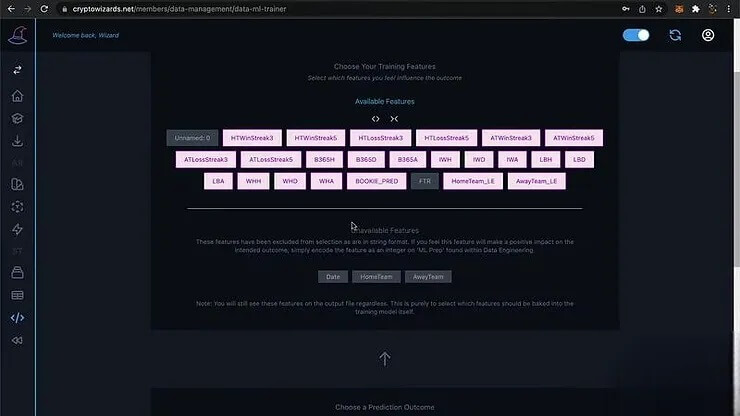
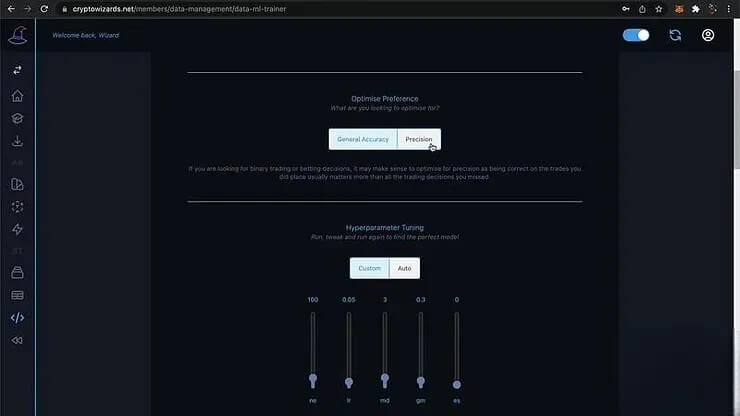
模型效能評估
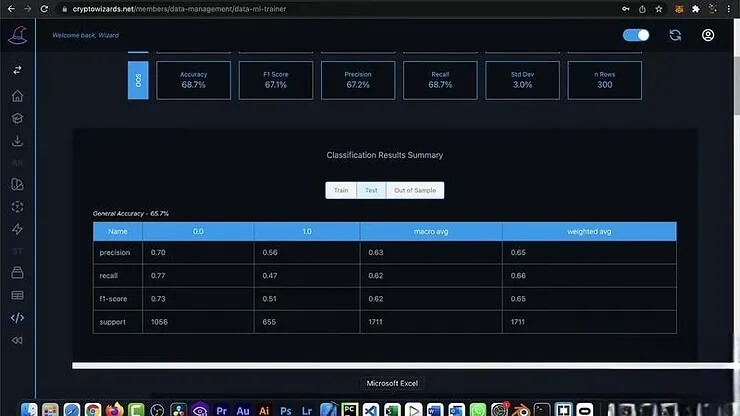
訓練完畢後,需要評估模型的效能,包括準確度、精準度、召回率等指標。從評估結果可以看出,模型在測試集上的準確度略高於博彩公司,說明模型具備一定的預測能力。透過模型的混淆矩陣,以及誤差曲線,進一步說明模型的表現。此外,訓練集、測試集和 OOS (Out of Sample) 數據也十分重要。訓練集用於訓練模型,測試集用於評估模型的泛化能力,而 OOS 數據則是用於驗證模型是否過度擬合。理想的模型應該在所有數據集上都能保持良好的效能。
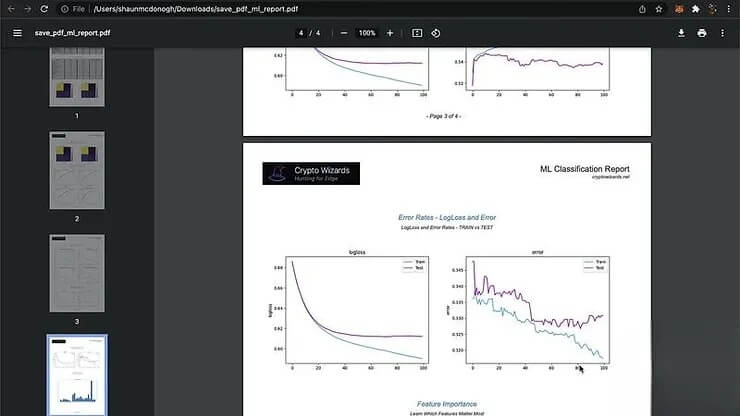
模型應用與未來發展
在研究機器學習於博弈交易的應用過程中,這些技術確實能協助交易者在賽前制定更為明智的決策。在數據集優化方面,可以利用多項策略來增強模型的預測能力。其中包括擴充特徵工程(feature engineering),引入更多元的數據源,如球員狀態指標(player form metrics)和球隊傷病報告(team injury reports)等。這些額外的特徵變量可以提升模型的泛化能力(generalization capability)和魯棒性(robustness)。通過持續優化數據集和調整模型架構,進一步提高預測準確率(prediction accuracy)。